Increase your app performance with Redis
Introduction
Redis is a high performance, in memory, key-value store. As one key feature, the actual values are not just plain old strings, but actual datastructures. So, Redis can be referred to as a data structure server.
An other key feature for this solution is that it’s written in C, and it has no external dependencies. Thus, it’s very easy to be installed on most POSIX systems like Linux, OS X. For example, on my Ubuntu 16.04 LTS laptop, for installing I’ve used the instructions in the download page.
Data types
Acording to some opinions, you can learn Redis from Zero to Master in just 30 minutes, and learning Redis is the most efficient way a programmer can spend 30 minutes. As we saw, Redis is a datastructure server, so while playing with Redis we will see a lot of data structures. To try Redis, you can simply go to a web console; or, if you downloaded and installed Redis (it’s simple!) you can just start a server in a terminal
$ src/redis-serverand a client in an other terminal
$ src/redis-cliRedis datatypes are well documented in the official documentation. Instead of repeating the excellent documentation, I will briefly mention some data structures with their usage:
-
Strings; strings are the most basic datastructure in Redis; are very useful for caching content, for example.
-
Lists; Lists in Redis are linked lists, so adding an element, retrieving the last element, can be done in O(1) time; this makes lists a good data structure in a social application, if we need the last social update fast.
-
Hashes; hashes are dictionaries, key-value associations; hashes are well optimized for low memory consumption, so it’s more memory efficient to have a hash with several fields rather than having several keys.
-
Sets; sets are unordered collections of unique items; are very useful for storing relationships between objects. For example, if we want to implement the tagging functionality, each tag can be a set.
-
Sorted sets; sorted sets are ordered collection of unique elements; leaderboards can be implemented using sorted sets.
-
Bitmaps; bitmaps are string, but with special operations so that each bit in the string can be 0 or 1; thus, can track many boolean values with low memory consumption; there is the bitcount operation, that will tell fast how many items are 1; thus, it’s very useful for real time analytics.
Production use
So far, we played a little at the terminal, with some data structures you learned back in school. And you might wonder, is this used in production? Then answer is yes, and a lot!
Instagram Engineering described a situation when, during a migration, they had to use Amazon EC2, in a memory efficient manner. They had to keep an picture id - user id association, for about 300 million pictures. The initial, trivial solution, to use a key-value pair for each picture id, ocuppied around 21 GB of data. As discussed earlier, hashes are optimized for low memory consumption. By using this data structure, and tweaking some Redis parameters for a good memory-CPU trade-off, they were able to reduce the space to under 5 GB.
The guys from GetSpool described an other situation when Redis saved the day: they used bitmaps to efficiently store data about daily active users. Basically, they created a bitmap for each day. For each bitmap, the bit at the user’s ID position was either true (if the user was logged that day) either false. So, they were able to both keep this data in a space-efficient manner, and to compute statistics fast.
Also, Redis is used a lot for the ‘basic’ cache feature. Stack Exchange, Pinterest, Github, and many others use Redis for caching.
Sample applications
Based on the production use, I decided to create some simple applications, to test the solution. I created two applications: sample-cache and bitmap-population-count. In the first example, I’ve used Redis just for the caching capabilities. In the second example, I’ve wanted to test the bitmap datatype, and the bitcount function.
Sample cache example
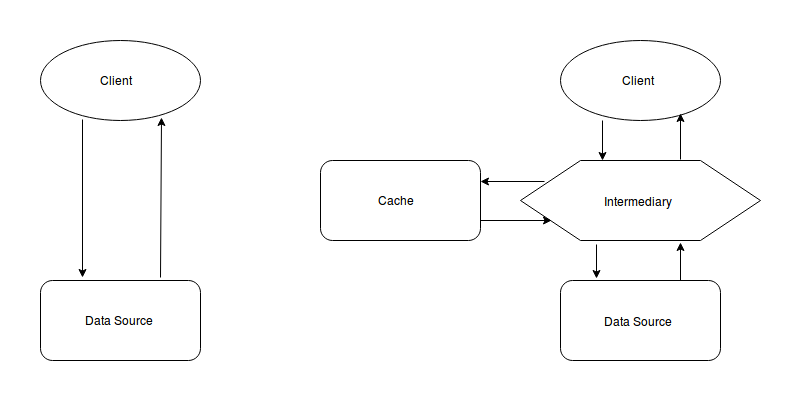
The picture above shows what a cache is. It is an intermediary system; it stores results having long retrieval times, so that future calls will no longer have to wait. The application exposes a controller, that pretty much follows this pattern:
@GetMapping("/value/{key}")
public String getValue(@PathVariable String key) {
logger.info("Receive request, key=<{}>", key);
String value = redisCacheService.retrieveValue(key);
if (value == null) {
logger.info("No value was found in cache for key=<{}>", key);
value = valueComputer.computeValue(key);
redisCacheService.setValue(key, value, 10 * 1000);
logger.info("For key=<{}> cached value=<{}>", key, value);
}
return value;
}The computation is simulated to take 5 seconds:
public String computeValue(String key) {
try {
Thread.sleep(5 * 1000);
} catch (Exception e) {
logger.error("An error occurred sleeping", e);
}
Random rand = new Random();
return key + "-value-" + rand.nextInt(100);
}The controller is self-explanatory: it receives the request to compute the value associated with a key. This computation takes 5 seconds, and the result is cached for 10 seconds. More information about running this project can be found on github.
Bitmap population count example
(image credit: http://www.promojam.com/how-it-works/real-time-analytics)
This project is, as well, on github. In this example, I wanted to test the bitcount function. For this, I generated a defined number of random numbers, between 0 and a defined value. For each number, the check if it’s smaller than an other defined value is made. The boolean value associated with this test is set in the number’s index position.
The controller looks like this:
@PostMapping("/experiments/create")
public String generateExperiment(@RequestBody ExperimentParameters experimentParameters) {
logger.info("Received create new experiment request, parameters=<{}>", experimentParameters);
redisService.createExperiment(experimentParameters);
logger.info("Finished populating experiment, <{}>", experimentParameters);
return experimentParameters.getKey();
}
@GetMapping("/experiments/{key}")
public long computePopulationCount(@PathVariable String key) {
logger.info("Received computePopulationCount request, key=<{}>", key);
long populationCount = redisService.populationCount(key);
logger.info("Finished computing populationCount, key=<{}>", key);
return populationCount;
}So, we have two endpoints, one for populating an experiment, the other for performing analytics on an experiment’s result.
This is how the experimented is populated, in an experiment:
public void createExperiment(ExperimentParameters experimentParameters) {
Random random = new Random();
Pipeline pipeline = jedis.pipelined();
for (long i = 0; i < experimentParameters.getPopulationNumber(); i++) {
boolean value = random.nextInt(experimentParameters.getMaxRandom()) < experimentParameters.getLessThan();
pipeline.setbit(experimentParameters.getKey(), i, value);
}
pipeline.sync();
}The model, ExperimentParameters, has several variables:
- key, the bitmap will have this key
- populationNumber: the number of random numbers to be generated;
- maxRandom: maximum value of each random number
- lessThan: for each generated random number, we check if it’s less than this value; the boolean value associated with this check is set in the bitmap, at the number’s position.
The analytics are performed quite straightforward, a bitcount call:
public long populationCount(String key) {
if (!keyExists(key)) {
throw new RuntimeException("Called population count for non-existing key: " + key);
}
return jedis.bitcount(key);
}I’ve tested with this model:
{
"key": "e1",
"populationNumber": 10000000,
"maxRandom": 1000,
"lessThan": 10
}Generating experiment data tooked about 11 seconds:
2018-04-22 16:49:35.477 INFO 21392 --- [nio-8080-exec-1] c.b.r.p.e.b.c.ExperimentsController : Received create new experiment request, parameters=<ExperimentParameters{key='e1', populationNumber=10000000, maxRandom=1000, lessThan=10}>
2018-04-22 16:49:46.572 INFO 21392 --- [nio-8080-exec-1] c.b.r.p.e.b.c.ExperimentsController : Finished populating experiment, <ExperimentParameters{key='e1', populationNumber=10000000, maxRandom=1000, lessThan=10}>So, we were able to generate 10 million random numbers, to compute 10 millions checks, and to call bitset 10 million times, in about 10 seconds. A note regarding implementation: the Redis pipelining feature was used. Each client, when sending a command, opens a TCP connection, closed after the answer. Without pipelining, opening and closing 10 million TCP connections drastically reduced our application’s performance: it tooked about 3 minutes for populating the same experiment.
But the surprise was when we performed the analytics:
2018-04-22 16:50:36.630 INFO 21392 --- [nio-8080-exec-2] c.b.r.p.e.b.c.ExperimentsController : Received computePopulationCount request, key=<e1>
2018-04-22 16:50:36.671 INFO 21392 --- [nio-8080-exec-2] c.b.r.p.e.b.c.ExperimentsController : Finished computing populationCount, key=<e1>So, it tooked about 11 milliseconds to compute how many of the 10 million boolean values are true!
Conclusions
As we saw, Redis is an easy to learn, easy to use, high performant, rich in functionalities, datastructure server. It’s no wander, at the date of writing this article, Redis was ranked nr.1 key-value store, by DB-Engines .
Bibliography
https://redis.io/
https://redis.io/topics/data-types-intro
https://redis.io/documentation
https://redis.io/commands
http://openmymind.net/redis.pdf
https://github.com/xetorthio/jedis
http://blog.getspool.com/2011/11/29/fast-easy-realtime-metrics-using-redis-bitmaps/
https://instagram-engineering.com/storing-hundreds-of-millions-of-simple-key-value-pairs-in-redis-1091ae80f74c
https://scaleyourcode.com/blog/article/25
https://meta.stackexchange.com/questions/69164/does-stack-exchange-use-caching-and-if-so-how/69172#69172
https://www.hakkalabs.co/articles/redis-at-pinterest-transcript
https://blog.github.com/2009-10-20-how-we-made-github-fast/
https://db-engines.com/en/ranking/key-value+store
http://www.promojam.com/how-it-works/real-time-analytics