Using Apache Ignite as a Hibernate second-level cache
Introduction
In Java world, Hibernate is a well known ORM and JPA provider. In short, Hibernate facilitates database access. For Java web applications, Hibernate is a often used solution. So, each time a web request arrives, database is queried and updated using this framework. Of course, some optimisations are possible, which send us to the subject of Hibernate caching.
Hibernate caching
Hibernate supports several levels of caching: first level cache (enabled by default), second level cache, query cache (same as first level cache). Before discussing these levels of cache, we need to discuss a little about Hibernate architecture.

Full Hibernate documentation can be found here; the relevant information is the existence of a class, Session, or EntityManager, it’s JPA equivalent. Database access is done using this class.
Example of a database call using Hibernate (taken from official documentation):
Photo photo = entityManager.createQuery(
"select p " +
"from Photo p " +
"where upper(caption) = upper(:caption) ", Photo.class )
.setParameter( "caption", "Nicolae Grigorescu" )
.getSingleResult();The Session object is a single-threaded, short-lived object, usually associated with a session (for example a web session, mapping a web request). So, there is a Session per each web request. The first level cache is associated with this object. Once a item is retrieved from the DB, it is stored here. Next time the same object is requested in the same web session, it is retrieved from the first level cache and not from DB. But if a different web request arrives, or the same web web request arrives later, database will be called again. To prevent this behavior, the concept of second level cache was born.
While the first level cache is implemented by Hibernate internally, the second level cache is optional, and is provided by a different solution. Hibernate needs to be configured to use a second level cache provider, and to use second level cache; later in this article, it will be explained how. On top of second level cache, a query cache can be added. Query cache is optional, and depends on second level cache.
A demo application was created for illustrating the concepts described in this article.
Demo application
The demo application, named ElectronicStore, manages an electronic store. I’s a REST API, retrieving data from the following database:

The database models an electronic store. The store has several branches, saved in the stores table (which id, city, address). Items to be sold are saved in the items table (having an id, serial number, name, description). Each item can have a review, saved in the reviews table (which id, item_id (item for which the review is created), nr_stars, comment). To indicate that an item can be found in a specific branch, a new table was created, items_location (having an id, an item_id (the item placed in the branch), store_id (the branch where the item is placed)).
There cannot be an electronic store without a logo, so here we have:
![]()
Project setup
The project uses PostgreSQL database, is implemented using Spring Framework and uses embedded Jetty as a web server. Maven is used as a build tool. A new database was configured as in following tutorial; then, the tables were created using this script. Jetty was used in embedded mode, and the build produces a .jar file; it can be easily run. Here is the project repository. As you can see in the repository, we have several controllers. We have a controller that saves items, updates items or retrieves them by id. Of course, each retrieve item by id request will have to access the DB. To see what DB calls the application makes, we will set property hibernate.show_sql to value true.
The project exposes the following API:
GET /item/{id}, retrieves an item according to it’s id. Example:
GET /item/4
Response:
{
"id": 4,
"serialNumber": "s-103 U",
"name": "Keystone stick",
"description": "Keystone 16 GB stick."
}
POST /item/save, saves an item. Example:
POST /item/save
{
"serialNumber": "s-103",
"name": "Keystone stick",
"description": "Keystone 16 GB stick."
}
PUT /item/update, updates an item. Example:
PUT /item/update
{
"id": 4,
"serialNumber": "s-103 U",
"name": "Keystone stick",
"description": "Keystone 16 GB stick."
}
GET /store/{id}, gets a store by id. Example:
GET /store/3
Response:
{
"id": 3,
"city": "Bucharest",
"address": "Plevnei Street nr. 8"
}
POST /store/save, saves a store. Example:
POST /store/save
{
"city": "Bucharest",
"address": "Averescu Street nr. 3"
}
PUT /store/update, updates a store. Example:
PUT /store/update
{
"id": 3,
"city": "Bucharest",
"address": "Plevnei Street nr. 8"
}
GET /store/list/{city}, lists all branches from a city. Example:
GET /store/list/Bucharest
Response:
[
{
"id": 2,
"city": "Bucharest",
"address": "Victoria Street nr. 25"
},
{
"id": 3,
"city": "Bucharest",
"address": "Plevnei Street nr. 8"
},
{
"id": 5,
"city": "Bucharest",
"address": "Averescu Street nr. 3"
}
]
GET /review/{id}, gets a review by id. Example:
GET /review/1
Response:
{
{
"id": 1,
"item": {
"id": 3,
"serialNumber": "s-102",
"name": "Keystone stick",
"description": "Keystone 8 GB stick."
},
"numberOfStars": 5,
"comment": "Excellent stick."
}
}
POST /review/save, saves a review. Example:
POST /review/save
{
"itemId": "2",
"numberOfStars": "4",
"comment": "Excellent computer."
}
GET /review/all/item/{itemId}, gets all reviews for a given item. Example:
GET /review/all/item/3
{
[
]
}
PUT /review/update/commentsbyrating, updates comments given a rating; used for illustrating cache invalidation when data is updated. Example:
PUT /review/update/commentsbyrating
{
"comment": "5 stars!",
"numberOfStars": 5
}
PUT /review/update/commentsbyrating/native, updates comments given a rating, this time using a native query; used for illustrating cache invalidation when data is updated. Example:
PUT /review/update/commentsbyrating/native
{
"comment": "5 stars!",
"numberOfStars": 5
}
To better understand the need of second level cache, let’s first run the project without caching. We will access the ‘GET /item/{id}’ endpoint, two times, each time with the same id.
At the first access, we will see the following in the logs:
2018-08-05 15:41:00 PM [qtp1983025922-15] DEBUG org.hibernate.SQL - select item0_.id as id1_0_0_, item0_.description as descript2_0_0_, item0_.name as name3_0_0_, item0_.serial_number as serial_n4_0_0_ from items item0_ where item0_.id=?
Hibernate: select item0_.id as id1_0_0_, item0_.description as descript2_0_0_, item0_.name as name3_0_0_, item0_.serial_number as serial_n4_0_0_ from items item0_ where item0_.id=?So, as we can see, the database was hit. And, at the second call, we can see the following:
2018-08-05 15:41:02 PM [qtp1983025922-11] DEBUG org.hibernate.SQL - select item0_.id as id1_0_0_, item0_.description as descript2_0_0_, item0_.name as name3_0_0_, item0_.serial_number as serial_n4_0_0_ from items item0_ where item0_.id=?
Hibernate: select item0_.id as id1_0_0_, item0_.description as descript2_0_0_, item0_.name as name3_0_0_, item0_.serial_number as serial_n4_0_0_ from items item0_ where item0_.id=?Unsurprisingly, the database is hit again. Two web requests, requiring the same data, arriving almost at the same time, will make a database call each. To improve performance, the second level cache concept was born.
Configure second-level cache
To use second-level cache, we must configure Hibernate to use second-level cache, and integrate a caching solution. To configure Hibernate to use second-level cache, we just have to set several properties:
hibernateProperties.setProperty("hibernate.cache.use_second_level_cache", "true");
hibernateProperties.setProperty("hibernate.cache.region.factory_class", "org.hibernate.cache.jcache.JCacheRegionFactory");For each entity that we want to cache, we will have to use the @Cacheable and @Cache annotations. For example:
@Entity
@Table(name = "items")
@Cacheable
@Cache(usage = CacheConcurrencyStrategy.READ_WRITE)
public class Item {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id")
private Long id;
@Column(name = "serial_number")
private String serialNumber;
@Column(name = "name")
private String name;
@Column(name = "description")
private String description;
}The @Cache annotation specifies a cache concurrency strategy. More details can be found here or here.
Hibernate stores cached entities using the id as key. So, repeated calls entityManager.find(Item.class, id);, for the same id, will retrieve items first time from the DB, then from the cache.
In addition, we can configure query cache too. For this, we need to configure Hibernate:
hibernateProperties.setProperty("hibernate.cache.use_query_cache", "true");And, we have to inform Hibernate about each query that we want to cache. For example:
entityManager.createQuery("select s from Store s where s.city=:city", Store.class)
.setParameter("city", city)
.setHint("org.hibernate.cacheable", true)
.getResultList();Query caches are useful for queries that are frequently executed with the same parameter values, and for entities that are in general unchanged. Our example is a perfect one for query caches: we are searching for branches by city; this search is quite frequently used, and the probability to search all stores in a given city, by different requests, is quite big. Also, we introduce new branches, or change their address, very seldom. Once a store query was cached, it will be invalidated each time we add or update a store.
Now, that we configured Hibernate, we need to integrate a caching provider. There are several cache solutions out there: Infinispan, Ehcache, Apache Ignite, Hazelcast, and so on. In Java world, since there are many libraries for cache, an standardization effort was made, that resulted in JSR 107, or JCache, specification. Since Hibernate 5.2.0, there is available a new Hibernate module, hibernate-jcache, for integrating a JCache provider as a second-level cache. Now, after we added hibernate-jcache, we only need to include a JCache provider in our project then configure Hibernate to use that provider:
<dependency>
<groupId>org.apache.ignite</groupId>
<artifactId>ignite-core</artifactId>
<version>2.6.0</version>
</dependency>hibernateProperties.setProperty("hibernate.javax.cache.provider", "org.apache.ignite.cache.CachingProvider");We integrated Apache Ignite as a JCache provider. If we wanted to use, let’s say, Ehcache as a JCache provider, we just had to use the following configuration:
<dependency>
<groupId>org.ehcache</groupId>
<artifactId>ehcache</artifactId>
<version>3.3.1</version>
</dependency>hibernateProperties.setProperty("hibernate.javax.cache.provider", "org.ehcache.jsr107.EhcacheCachingProvider");This is the power of standardization: for integrating a different solution, we just have to change some configurations. Of course, this is not always so easy, for example maybe we will have to configure each solution differently.
Testing second-level cache
Now, that we configured Hibernate second-level cache, we can test our configuration. We will start two instances of our ElectronicStore application. In two different terminal windows, execute the following (after the project was compiled):
java -jar target/ElectronicStore.jar port:8080java -jar target/ElectronicStore.jar port:8081We started two instances of ElectronicStore, one running on 8080 and the other on 8081. Without any other configuration, each instance will have it’s own Apache Ignite, running in server mode, non-communicating. So cache will not be shared between instances. This is how the cluster looks like now:
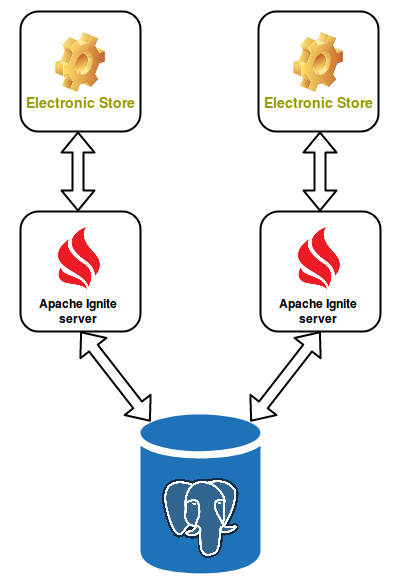
We can easily see this, first of all, when we start the instances: in the logs, we see messages like this:
Topology snapshot [ver=1, servers=1, clients=0, CPUs=4, offheap=3.1GB, heap=3.5GB]To further see this, we will call GET /item/4 endpoint, two times, for each instance. In the logs, we will see
2018-08-05 21:37:08 PM [qtp1983025922-16] DEBUG org.hibernate.cache.spi.support.AbstractReadWriteAccess - Getting cached data from region [`com.bstirbat.sample.electronicstore.model.db.Item` (AccessType[read-write])] by key [com.bstirbat.sample.electronicstore.model.db.Item#4]
2018-08-05 21:37:08 PM [qtp1983025922-16] DEBUG org.hibernate.cache.spi.support.AbstractReadWriteAccess - Cache miss : region = `com.bstirbat.sample.electronicstore.model.db.Item`, key = `com.bstirbat.sample.electronicstore.model.db.Item#4`
2018-08-05 21:37:08 PM [qtp1983025922-16] DEBUG org.hibernate.SQL - select item0_.id as id1_0_0_, item0_.description as descript2_0_0_, item0_.name as name3_0_0_, item0_.serial_number as serial_n4_0_0_ from items item0_ where item0_.id=?
Hibernate: select item0_.id as id1_0_0_, item0_.description as descript2_0_0_, item0_.name as name3_0_0_, item0_.serial_number as serial_n4_0_0_ from items item0_ where item0_.id=?
2018-08-05 21:37:08 PM [qtp1983025922-16] DEBUG org.hibernate.cache.spi.support.AbstractReadWriteAccess - Caching data from load [region=`com.bstirbat.sample.electronicstore.model.db.Item` (AccessType[read-write])] : key[com.bstirbat.sample.electronicstore.model.db.Item#4] -> value[CacheEntry(com.bstirbat.sample.electronicstore.model.db.Item)]
2018-08-05 21:37:10 PM [qtp1983025922-11] DEBUG org.hibernate.cache.spi.support.AbstractReadWriteAccess - Getting cached data from region [`com.bstirbat.sample.electronicstore.model.db.Item` (AccessType[read-write])] by key [com.bstirbat.sample.electronicstore.model.db.Item#4]
2018-08-05 21:37:10 PM [qtp1983025922-11] DEBUG org.hibernate.cache.spi.support.AbstractReadWriteAccess - Checking readability of read-write cache item [timestamp=`6281192358690816`, version=`null`] : txTimestamp=`6281192368697344`
2018-08-05 21:37:10 PM [qtp1983025922-11] DEBUG org.hibernate.cache.spi.support.AbstractReadWriteAccess - Cache hit : region = `com.bstirbat.sample.electronicstore.model.db.Item`, key = `com.bstirbat.sample.electronicstore.model.db.Item#4`for the fist instance and
2018-08-05 21:38:01 PM [qtp1983025922-15] DEBUG org.hibernate.cache.spi.support.AbstractReadWriteAccess - Getting cached data from region [`com.bstirbat.sample.electronicstore.model.db.Item` (AccessType[read-write])] by key [com.bstirbat.sample.electronicstore.model.db.Item#4]
2018-08-05 21:38:01 PM [qtp1983025922-15] DEBUG org.hibernate.cache.spi.support.AbstractReadWriteAccess - Cache miss : region = `com.bstirbat.sample.electronicstore.model.db.Item`, key = `com.bstirbat.sample.electronicstore.model.db.Item#4`
2018-08-05 21:38:01 PM [qtp1983025922-15] DEBUG org.hibernate.SQL - select item0_.id as id1_0_0_, item0_.description as descript2_0_0_, item0_.name as name3_0_0_, item0_.serial_number as serial_n4_0_0_ from items item0_ where item0_.id=?
Hibernate: select item0_.id as id1_0_0_, item0_.description as descript2_0_0_, item0_.name as name3_0_0_, item0_.serial_number as serial_n4_0_0_ from items item0_ where item0_.id=?
2018-08-05 21:38:01 PM [qtp1983025922-15] DEBUG org.hibernate.cache.spi.support.AbstractReadWriteAccess - Caching data from load [region=`com.bstirbat.sample.electronicstore.model.db.Item` (AccessType[read-write])] : key[com.bstirbat.sample.electronicstore.model.db.Item#4] -> value[CacheEntry(com.bstirbat.sample.electronicstore.model.db.Item)]
2018-08-05 21:38:02 PM [qtp1983025922-11] DEBUG org.hibernate.cache.spi.support.AbstractReadWriteAccess - Getting cached data from region [`com.bstirbat.sample.electronicstore.model.db.Item` (AccessType[read-write])] by key [com.bstirbat.sample.electronicstore.model.db.Item#4]
2018-08-05 21:38:02 PM [qtp1983025922-11] DEBUG org.hibernate.cache.spi.support.AbstractReadWriteAccess - Checking readability of read-write cache item [timestamp=`6281192577867776`, version=`null`] : txTimestamp=`6281192581627904`
2018-08-05 21:38:02 PM [qtp1983025922-11] DEBUG org.hibernate.cache.spi.support.AbstractReadWriteAccess - Cache hit : region = `com.bstirbat.sample.electronicstore.model.db.Item`, key = `com.bstirbat.sample.electronicstore.model.db.Item#4`for the second one.
As we can see, cache works, but it is not shared between instances.
Luckly, Apache Ignite runs in cluster mode, so, we can configure the Ignite cache, for each instance, to run in client mode and to connect to an Ignite instance running in server mode. To do this, we will write a configuration file for Ignite cache, specifying that we want the cache to run in client mode:
<bean name="igniteConfiguration" class="org.apache.ignite.configuration.IgniteConfiguration">
<property name="clientMode" value="true"/>
</bean>Next, we will instruct Hibernate to use this configuration file:
hibernateProperties.setProperty("hibernate.javax.cache.uri", "file:///path/to/config.xml");The application is ready. We also have to prepare the Apache Ignite server. For this, we will download, as specified here, Apache Ignite, we will unzip it, and we will go which a terminal window to the folder where we extracted the archive. To start the Apache server:
export IGNITE_HOME=/home/bogdan/Applications/apache_ignite/apache-ignite-fabric-2.6.0-bin
$IGNITE_HOME/bin/ignite.shOnce the server is started we will see the following in logs:
Topology snapshot [ver=1, servers=1, clients=0, CPUs=4, offheap=3.1GB, heap=1.0GB]Apache Ignite also has a cmd manager. To use it, we will open a new terminal window, go to the same folder, and we will start the manager:
export IGNITE_HOME=/home/bogdan/Applications/apache_ignite/apache-ignite-fabric-2.6.0-bin
$IGNITE_HOME/bin/ignitevisorcmd.shNext, after we updated the source code, we will recompile it and restart both instances. We will now see the following in the logs:
Topology snapshot [ver=3, servers=1, clients=1, CPUs=4, offheap=3.1GB, heap=4.5GB]when we start the first instance and
Topology snapshot [ver=4, servers=1, clients=2, CPUs=4, offheap=3.1GB, heap=7.9GB]when we start the second one. In the Apache Ignite server logs, we see the following:
21:57:54] Topology snapshot [ver=3, servers=1, clients=1, CPUs=4, offheap=3.1GB, heap=4.5GB]
[21:57:54] ^-- Node [id=D1C5E3C6-46EE-43A0-9279-9F100E4720EE, clusterState=ACTIVE]
[21:57:54] Data Regions Configured:
[21:57:54] ^-- default [initSize=256.0 MiB, maxSize=3.1 GiB, persistenceEnabled=false]
[21:59:16] Topology snapshot [ver=4, servers=1, clients=2, CPUs=4, offheap=3.1GB, heap=7.9GB]
[21:59:16] ^-- Node [id=D1C5E3C6-46EE-43A0-9279-9F100E4720EE, clusterState=ACTIVE]
[21:59:16] Data Regions Configured:
[21:59:16] ^-- default [initSize=256.0 MiB, maxSize=3.1 GiB, persistenceEnabled=false]So, when we started the ElectronicStore instances, the Ignite clients connected to the Ignite server.
Now, the cluster looks like this:

Ok, now we are ready to repeat the experiment. We will see:
2018-08-05 22:10:28 PM [qtp1983025922-13] DEBUG org.hibernate.cache.spi.support.AbstractReadWriteAccess - Getting cached data from region [`com.bstirbat.sample.electronicstore.model.db.Item` (AccessType[read-write])] by key [com.bstirbat.sample.electronicstore.model.db.Item#4]
2018-08-05 22:10:28 PM [qtp1983025922-13] DEBUG org.hibernate.cache.spi.support.AbstractReadWriteAccess - Cache miss : region = `com.bstirbat.sample.electronicstore.model.db.Item`, key = `com.bstirbat.sample.electronicstore.model.db.Item#4`
2018-08-05 22:10:28 PM [qtp1983025922-13] DEBUG org.hibernate.SQL - select item0_.id as id1_0_0_, item0_.description as descript2_0_0_, item0_.name as name3_0_0_, item0_.serial_number as serial_n4_0_0_ from items item0_ where item0_.id=?
Hibernate: select item0_.id as id1_0_0_, item0_.description as descript2_0_0_, item0_.name as name3_0_0_, item0_.serial_number as serial_n4_0_0_ from items item0_ where item0_.id=?
2018-08-05 22:10:28 PM [qtp1983025922-13] DEBUG org.hibernate.cache.spi.support.AbstractReadWriteAccess - Caching data from load [region=`com.bstirbat.sample.electronicstore.model.db.Item` (AccessType[read-write])] : key[com.bstirbat.sample.electronicstore.model.db.Item#4] -> value[CacheEntry(com.bstirbat.sample.electronicstore.model.db.Item)]
2018-08-05 22:10:30 PM [qtp1983025922-11] DEBUG org.hibernate.cache.spi.support.AbstractReadWriteAccess - Getting cached data from region [`com.bstirbat.sample.electronicstore.model.db.Item` (AccessType[read-write])] by key [com.bstirbat.sample.electronicstore.model.db.Item#4]
2018-08-05 22:10:30 PM [qtp1983025922-11] DEBUG org.hibernate.cache.spi.support.AbstractReadWriteAccess - Checking readability of read-write cache item [timestamp=`6281200552357888`, version=`null`] : txTimestamp=`6281200559611904`
2018-08-05 22:10:30 PM [qtp1983025922-11] DEBUG org.hibernate.cache.spi.support.AbstractReadWriteAccess - Cache hit : region = `com.bstirbat.sample.electronicstore.model.db.Item`, key = `com.bstirbat.sample.electronicstore.model.db.Item#4`in the first instance’s logs and
2018-08-05 22:11:17 PM [qtp1983025922-17] DEBUG org.hibernate.cache.spi.support.AbstractReadWriteAccess - Getting cached data from region [`com.bstirbat.sample.electronicstore.model.db.Item` (AccessType[read-write])] by key [com.bstirbat.sample.electronicstore.model.db.Item#4]
2018-08-05 22:11:17 PM [qtp1983025922-17] DEBUG org.hibernate.cache.spi.support.AbstractReadWriteAccess - Checking readability of read-write cache item [timestamp=`6281200552357888`, version=`null`] : txTimestamp=`6281200754049024`
2018-08-05 22:11:17 PM [qtp1983025922-17] DEBUG org.hibernate.cache.spi.support.AbstractReadWriteAccess - Cache hit : region = `com.bstirbat.sample.electronicstore.model.db.Item`, key = `com.bstirbat.sample.electronicstore.model.db.Item#4`
2018-08-05 22:11:19 PM [qtp1983025922-11] DEBUG org.hibernate.cache.spi.support.AbstractReadWriteAccess - Getting cached data from region [`com.bstirbat.sample.electronicstore.model.db.Item` (AccessType[read-write])] by key [com.bstirbat.sample.electronicstore.model.db.Item#4]
2018-08-05 22:11:19 PM [qtp1983025922-11] DEBUG org.hibernate.cache.spi.support.AbstractReadWriteAccess - Checking readability of read-write cache item [timestamp=`6281200552357888`, version=`null`] : txTimestamp=`6281200759140352`
2018-08-05 22:11:19 PM [qtp1983025922-11] DEBUG org.hibernate.cache.spi.support.AbstractReadWriteAccess - Cache hit : region = `com.bstirbat.sample.electronicstore.model.db.Item`, key = `com.bstirbat.sample.electronicstore.model.db.Item#4`in the second one. So, we can see, the data was cached between the two instances of ElectronicStore.
We can inspect the cache content which the console manager. Following the instructions, we will see this:
| o.a.i.i.binary.BinaryObjectImpl | org.hibernate.cache.internal.CacheKeyImplementation [hash=-567327800, hashCode=124, entityOrRoleName=com.bstirbat.sample.electronicstore.model.db.Item, tenantId=null, id=4, type=org.hibernate.type.LongType [idHash=1828168222, hash=-1782100715, sqlTypes=[-5], sqlTypeDescriptor=org.hibernate.type.descriptor.sql.BigIntTypeDescriptor [idHash=407453846, hash=1], dictatedSize=org.hibernate.engine.jdbc.Size [idHash=525268787, hash=891931472, lobMultiplier=org.hibernate.engine.jdbc.Size$LobMultiplier [ordinal=0], precision=19, length=255, scale=2], javaTypeDescriptor=org.hibernate.type.descriptor.java.LongTypeDescriptor [idHash=602421947, hash=129286524, comparator=org.hibernate.internal.util.compare.ComparableComparator [idHash=1266132634, hash=1], mutabilityPlan=org.hibernate.type.descriptor.java.ImmutableMutabilityPlan [idHash=1658497875, hash=1], type=class java.lang.Long]]] | o.a.i.i.binary.BinaryObjectImpl | org.hibernate.cache.spi.support.AbstractReadWriteAccess$Item [hash=273378519, value=org.hibernate.cache.spi.entry.StandardCacheEntryImpl [idHash=791613178, hash=1409925332, subclass=com.bstirbat.sample.electronicstore.model.db.Item, disassembledState=[Keystone 16 GB stick., Keystone stick, s-103 U, version=null], version=null, timestamp=6281200552357888] |We can see both the key used for cache (4 in our example) and the cached data, in a disassembled state (Keystone 16 GB stick., Keystone stick, s-103 U, version=null).
Let’s further play with the cache. If we update the same item, will the cache be invalidated?
This is what we see in logs:
2018-08-05 22:20:12 PM [qtp1983025922-13] DEBUG org.hibernate.cache.spi.support.AbstractReadWriteAccess - Getting cached data from region [`com.bstirbat.sample.electronicstore.model.db.Item` (AccessType[read-write])] by key [com.bstirbat.sample.electronicstore.model.db.Item#4]
2018-08-05 22:20:12 PM [qtp1983025922-13] DEBUG org.hibernate.cache.spi.support.AbstractReadWriteAccess - Checking readability of read-write cache item [timestamp=`6281200552357888`, version=`null`] : txTimestamp=`6281202942046208`
2018-08-05 22:20:12 PM [qtp1983025922-13] DEBUG org.hibernate.cache.spi.support.AbstractReadWriteAccess - Cache hit : region = `com.bstirbat.sample.electronicstore.model.db.Item`, key = `com.bstirbat.sample.electronicstore.model.db.Item#4`
2018-08-05 22:20:12 PM [qtp1983025922-13] DEBUG org.hibernate.cache.spi.support.AbstractReadWriteAccess - Locking cache item [region=`com.bstirbat.sample.electronicstore.model.db.Item` (AccessType[read-write])] : `com.bstirbat.sample.electronicstore.model.db.Item#4` (timeout=6281203187863552, version=null)
2018-08-05 22:20:12 PM [qtp1983025922-13] DEBUG org.hibernate.SQL - update items set description=?, name=?, serial_number=? where id=?
Hibernate: update items set description=?, name=?, serial_number=? where id=?
2018-08-05 22:20:12 PM [qtp1983025922-13] DEBUG org.hibernate.cache.internal.TimestampsCacheEnabledImpl - Pre-invalidating space [items], timestamp: 6281203188023296
2018-08-05 22:20:12 PM [qtp1983025922-13] DEBUG org.hibernate.cache.internal.TimestampsCacheEnabledImpl - Invalidating space [items], timestamp: 6281202942410752So, we can see that the item was updated in database, and the cache was invalidated (as expected). But, we can see with the console manager that the cache was updated too. A further GET call will confirm that, indeed, updated data is retrieved from the cache, and not from the database.
Next, let’s play with the query cache a little. The endpoint GET /store/list/{city} uses a cached query behind the scenes.
We will hit the endpoint, two times, which the same value of city each time. This is what we see in logs:
2018-08-05 22:33:21 PM [qtp1983025922-16] INFO org.hibernate.hql.internal.QueryTranslatorFactoryInitiator - HHH000397: Using ASTQueryTranslatorFactory
2018-08-05 22:33:22 PM [qtp1983025922-16] DEBUG org.hibernate.cache.internal.QueryResultsCacheImpl - Checking cached query results in region: default-query-results-region
2018-08-05 22:33:22 PM [qtp1983025922-16] DEBUG org.hibernate.cache.internal.QueryResultsCacheImpl - Query results were not found in cache
2018-08-05 22:33:22 PM [qtp1983025922-16] DEBUG org.hibernate.SQL - select store0_.id as id1_3_, store0_.address as address2_3_, store0_.city as city3_3_ from stores store0_ where store0_.city=?
Hibernate: select store0_.id as id1_3_, store0_.address as address2_3_, store0_.city as city3_3_ from stores store0_ where store0_.city=?
2018-08-05 22:33:22 PM [qtp1983025922-16] DEBUG org.hibernate.cache.spi.support.AbstractReadWriteAccess - Caching data from load [region=`com.bstirbat.sample.electronicstore.model.db.Store` (AccessType[read-write])] : key[com.bstirbat.sample.electronicstore.model.db.Store#2] -> value[CacheEntry(com.bstirbat.sample.electronicstore.model.db.Store)]
2018-08-05 22:33:22 PM [qtp1983025922-16] DEBUG org.hibernate.cache.spi.support.AbstractReadWriteAccess - Caching data from load [region=`com.bstirbat.sample.electronicstore.model.db.Store` (AccessType[read-write])] : key[com.bstirbat.sample.electronicstore.model.db.Store#3] -> value[CacheEntry(com.bstirbat.sample.electronicstore.model.db.Store)]
2018-08-05 22:33:22 PM [qtp1983025922-16] DEBUG org.hibernate.cache.spi.support.AbstractReadWriteAccess - Caching data from load [region=`com.bstirbat.sample.electronicstore.model.db.Store` (AccessType[read-write])] : key[com.bstirbat.sample.electronicstore.model.db.Store#5] -> value[CacheEntry(com.bstirbat.sample.electronicstore.model.db.Store)]
2018-08-05 22:33:22 PM [qtp1983025922-16] DEBUG org.hibernate.cache.internal.QueryResultsCacheImpl - Caching query results in region: default-query-results-region; timestamp=6281206177394688
2018-08-05 22:33:23 PM [qtp1983025922-14] DEBUG org.hibernate.cache.internal.QueryResultsCacheImpl - Checking cached query results in region: default-query-results-region
2018-08-05 22:33:23 PM [qtp1983025922-14] DEBUG org.hibernate.cache.internal.QueryResultsCacheImpl - Returning cached query results
2018-08-05 22:33:23 PM [qtp1983025922-14] DEBUG org.hibernate.cache.spi.support.AbstractReadWriteAccess - Getting cached data from region [`com.bstirbat.sample.electronicstore.model.db.Store` (AccessType[read-write])] by key [com.bstirbat.sample.electronicstore.model.db.Store#2]
2018-08-05 22:33:23 PM [qtp1983025922-14] DEBUG org.hibernate.cache.spi.support.AbstractReadWriteAccess - Checking readability of read-write cache item [timestamp=`6281206177394688`, version=`null`] : txTimestamp=`6281206184144896`
2018-08-05 22:33:23 PM [qtp1983025922-14] DEBUG org.hibernate.cache.spi.support.AbstractReadWriteAccess - Cache hit : region = `com.bstirbat.sample.electronicstore.model.db.Store`, key = `com.bstirbat.sample.electronicstore.model.db.Store#2`
2018-08-05 22:33:23 PM [qtp1983025922-14] DEBUG org.hibernate.cache.spi.support.AbstractReadWriteAccess - Getting cached data from region [`com.bstirbat.sample.electronicstore.model.db.Store` (AccessType[read-write])] by key [com.bstirbat.sample.electronicstore.model.db.Store#3]
2018-08-05 22:33:23 PM [qtp1983025922-14] DEBUG org.hibernate.cache.spi.support.AbstractReadWriteAccess - Checking readability of read-write cache item [timestamp=`6281206177394688`, version=`null`] : txTimestamp=`6281206184144896`
2018-08-05 22:33:23 PM [qtp1983025922-14] DEBUG org.hibernate.cache.spi.support.AbstractReadWriteAccess - Cache hit : region = `com.bstirbat.sample.electronicstore.model.db.Store`, key = `com.bstirbat.sample.electronicstore.model.db.Store#3`
2018-08-05 22:33:23 PM [qtp1983025922-14] DEBUG org.hibernate.cache.spi.support.AbstractReadWriteAccess - Getting cached data from region [`com.bstirbat.sample.electronicstore.model.db.Store` (AccessType[read-write])] by key [com.bstirbat.sample.electronicstore.model.db.Store#5]
2018-08-05 22:33:23 PM [qtp1983025922-14] DEBUG org.hibernate.cache.spi.support.AbstractReadWriteAccess - Checking readability of read-write cache item [timestamp=`6281206177394688`, version=`null`] : txTimestamp=`6281206184144896`
2018-08-05 22:33:23 PM [qtp1983025922-14] DEBUG org.hibernate.cache.spi.support.AbstractReadWriteAccess - Cache hit : region = `com.bstirbat.sample.electronicstore.model.db.Store`, key = `com.bstirbat.sample.electronicstore.model.db.Store#5`Basically, the query result was cached, and only one select statement was performed. From the console manager, we can see that we have a cache query results region, where the id of results are stored.
An other experiment can be to create an other store. We will see, the query cache is invalidated (as expected).
An other endpoint has a cached query behind the scenes, GET /review/all/item/{itemId}. First, let’s hit this endpoint to cache the result, then let’s update the reviews, and see what happens with the stores and reviews query caches.
First, we will update using PUT /review/update/commentsbyrating; this will update the DB using a HQL query. We can see, the stores cache is still valid, but the reviews cache is invalidated.
Next, we will update using PUT /review/update/commentsbyrating/native; this will update the DB using a native SQL query. Now, all the second level cache is invalidated. Hibernate cannow know what items are affected by a native querry, so all second level cache is invalidated.
2018-08-05 22:59:22 PM [qtp1983025922-15] DEBUG org.hibernate.cache.internal.TimestampsCacheEnabledImpl - Invalidating space [reviews], timestamp: 6281212568227840
2018-08-05 22:59:22 PM [qtp1983025922-15] DEBUG org.hibernate.cache.internal.TimestampsCacheEnabledImpl - Invalidating space [stores], timestamp: 6281212568227840
2018-08-05 22:59:22 PM [qtp1983025922-15] DEBUG org.hibernate.cache.internal.TimestampsCacheEnabledImpl - Invalidating space [items_location], timestamp: 6281212568227840
2018-08-05 22:59:22 PM [qtp1983025922-15] DEBUG org.hibernate.cache.internal.TimestampsCacheEnabledImpl - Invalidating space [items], timestamp: 6281212568227840In order to stop a native query from invalidating all the cache, there is a solution implemented in Hibernate but not described by the JPA standard. The solution, is described here: nativeQuery.unwrap(org.hibernate.SQLQuery.class).addSynchronizedEntityClass(Foo.class).
Conclusions
We described caching in Hibernate, and the need for second level cache. We configured second level cache using hibernate-jcache and a JCache provider. Then, we performed some experiments with the second level cache. We noticed that a native query will invalidate all second level cache (and query cache), unless we use an non-JPA standard, Hibernate specific solution.
The project is hosted on Github.
Links
https://www.boraji.com/hibernate-5-jcache-ehcache-3-configuration-example
http://www.baeldung.com/hibernate-second-level-cache
http://docs.jboss.org/hibernate/orm/5.3/userguide/html_single/Hibernate_User_Guide.html#caching
http://www.eclipse.org/jetty/documentation/9.3.x/embedding-jetty.html
https://github.com/fernandospr/spring-jetty-example/blob/master/src/main/java/com/fernandospr/example/server/EmbeddedJetty.java
http://www.baeldung.com/the-persistence-layer-with-spring-and-jpa
https://ignite.apache.org
https://ignite.apache.org/use-cases/caching/hibernate-l2-cache.html
http://www.baeldung.com/hibernate-5-spring
https://docs.spring.io/spring/docs/5.0.8.RELEASE/spring-framework-reference/data-access.html
https://stackoverflow.com/questions/32269192/spring-no-entitymanager-with-actual-transaction-available-for-current-thread
https://stackoverflow.com/questions/47315106/failed-to-write-http-message-org-springframework-http-converter-httpmessagenotw
https://www.digitalocean.com/community/tutorials/how-to-install-and-use-postgresql-on-ubuntu-16-04
https://medium.com/coding-blocks/creating-user-database-and-adding-access-on-postgresql-8bfcd2f4a91e
http://www.postgresqltutorial.com/postgresql-serial/
https://chartio.com/resources/tutorials/how-to-define-an-auto-increment-primary-key-in-postgresql/